当我们在 SQL Server 中处理大规模数据插入(INSERT)操作时,往往会因为记录量庞大、日志写入多、并发竞争等原因导致性能下降。 TABLOCK 提示(Hint)是 SQL Server 提供的一种有效方式,可以通过减少日志记录和允许并行加载来提升插入性能。下面,我们就来详细讨论它的原理、优势及使用方式,并给出一个类似的示例供参考。
什么是 TABLOCK Hint 在执行 INSERT、UPDATE 或 DELETE 等操作时, TABLOCK 会在目标表上获取 表级锁 ,并对其施加一段时间的 模式修复锁 (Sch-M) 。这意味着在整个操作执行期间,其他事务无法修改该表的架构或进行并发写入。虽然听起来会牺牲一定的并发能力,但对于一次性地批量导入或更新大量数据的场景,该锁策略可以激活更多的优化:
最小日志记录 可以显著减少日志写入量,尤其在批量插入时不再逐行写入日志,而是采用批量式记录的方式。 并行化 在表被完全锁定后,SQL Server 可以尝试使用多个线程并行插入数据,从而缩短整体执行时间。 使用场景 一般来说, TABLOCK 适合以下场景:
需要一次性插入 大量数据 ,并且频繁的小批次插入不多。 能够接受在插入过程中 暂时锁定 目标表(如批处理或离线数据导入)。 提高性能速度比表可用性更加重要的批量场景,例如 ETL 流程 、 数据仓库加载 或者 大规模临时表作业 。 需要利用 SQL Server 并行处理能力,尽快完成数据插入。 示例:在 AdventureWorks2022 中使用 TABLOCK 以下示例展示了如何在插入数据时应用 TABLOCK ,并与不使用 TABLOCK 的情况进行对比。假设我们有一张目标表 Sales.SalesOrderDetailBulk 用来存储大量明细数据,源表为 Sales.SalesOrderDetail 。
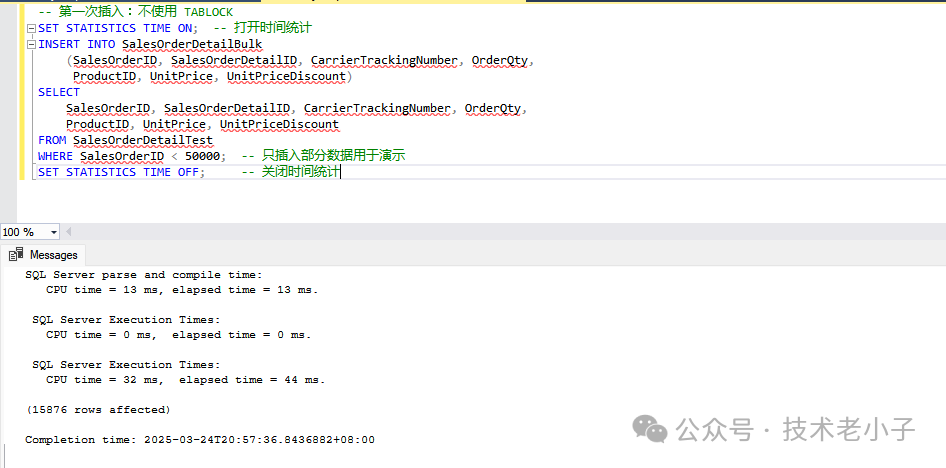
创建或清理目标表 -- 如果存在测试表,先删除 IF OBJECT_ID('SalesOrderDetailTest', 'U') IS NOT NULL DROP TABLE Sales.SalesOrderDetailTest; GO -- 创建测试表,模仿原始表结构 CREATE TABLE SalesOrderDetailTest ( SalesOrderID INT NOT NULL , SalesOrderDetailID INT IDENTITY ( 1 , 1 ) PRIMARY KEY , CarrierTrackingNumber NVARCHAR ( 25 ) NULL , OrderQty SMALLINT NOT NULL , ProductID INT NOT NULL , SpecialOfferID INT NOT NULL , UnitPrice MONEY NOT NULL , UnitPriceDiscount MONEY NOT NULL , LineTotal AS (OrderQty * UnitPrice * ( 1 - UnitPriceDiscount)) PERSISTED, ); GO -- 批量插入测试数据的存储过程 CREATE OR ALTER PROCEDURE GenerateSalesOrderDetailTestData @NumberOfRecords INT = 100000 AS BEGIN SET NOCOUNT ON ; -- 使用公共表表达式(CTE)生成测试数据 ;WITH NumberedRows AS ( SELECT TOP (@NumberOfRecords) ROW_NUMBER() OVER ( ORDER BY ( SELECT NULL )) AS RowNum FROM sys.objects o1 CROSS JOIN sys.objects o2 ) INSERT INTO SalesOrderDetailTest ( SalesOrderID, CarrierTrackingNumber, OrderQty, ProductID, SpecialOfferID, UnitPrice, UnitPriceDiscount ) SELECT -- 随机生成 SalesOrderID ABS ( CHECKSUM (NEWID()) % 50000 ) + 1 AS SalesOrderID, -- 随机生成跟踪号 'TRK' + RIGHT ( '00000' + CAST ( ABS ( CHECKSUM (NEWID()) % 99999 ) AS VARCHAR ( 5 )), 5 ) AS CarrierTrackingNumber, -- 随机订单数量 ABS ( CHECKSUM (NEWID()) % 10 ) + 1 AS OrderQty, -- 随机产品ID(假设产品ID范围) ABS ( CHECKSUM (NEWID()) % 1000 ) + 1 AS ProductID, -- 随机特殊优惠ID ABS ( CHECKSUM (NEWID()) % 10 ) + 1 AS SpecialOfferID, -- 随机单价 ROUND ( ABS ( CHECKSUM (NEWID())) % 1000 + 10.00 , 2 ) AS UnitPrice, -- 随机折扣 ROUND ( ABS ( CHECKSUM (NEWID())) % 20 / 100.00 , 2 ) AS UnitPriceDiscount FROM NumberedRows; END GO -- 执行存储过程生成测试数据 EXEC GenerateSalesOrderDetailTestData @NumberOfRecords = 500000 ; GO -- 创建索引以提高查询性能 CREATE NONCLUSTERED INDEX IX_SalesOrderDetailTest_ProductID ON SalesOrderDetailTest (ProductID); CREATE NONCLUSTERED INDEX IX_SalesOrderDetailTest_SalesOrderID ON SalesOrderDetailTest (SalesOrderID); -- 如果已存在,先删除后再创建 IF OBJECT_ID('SalesOrderDetailBulk', 'U') IS NOT NULL DROP TABLE SalesOrderDetailBulk; GO -- 创建一张用于演示的表,结构与 Sales.SalesOrderDetail 相似 CREATE TABLE SalesOrderDetailBulk ( SalesOrderID INT , SalesOrderDetailID INT , CarrierTrackingNumber NVARCHAR ( 25 ), OrderQty SMALLINT , ProductID INT , UnitPrice MONEY, UnitPriceDiscount MONEY, LineTotal AS (OrderQty * UnitPrice) ); GO 不使用 TABLOCK 的插入操作 -- 第一次插入:不使用 TABLOCK SET STATISTICS TIME ON ; -- 打开时间统计 INSERT INTO SalesOrderDetailBulk (SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber, OrderQty, ProductID, UnitPrice, UnitPriceDiscount) SELECT SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber, OrderQty, ProductID, UnitPrice, UnitPriceDiscount FROM SalesOrderDetailTest WHERE SalesOrderID < 50000 ; -- 只插入部分数据用于演示 SET STATISTICS TIME OFF ; -- 关闭时间统计
观察执行结果,记录 CPU 时间、总持续时间(Elapsed Time)。
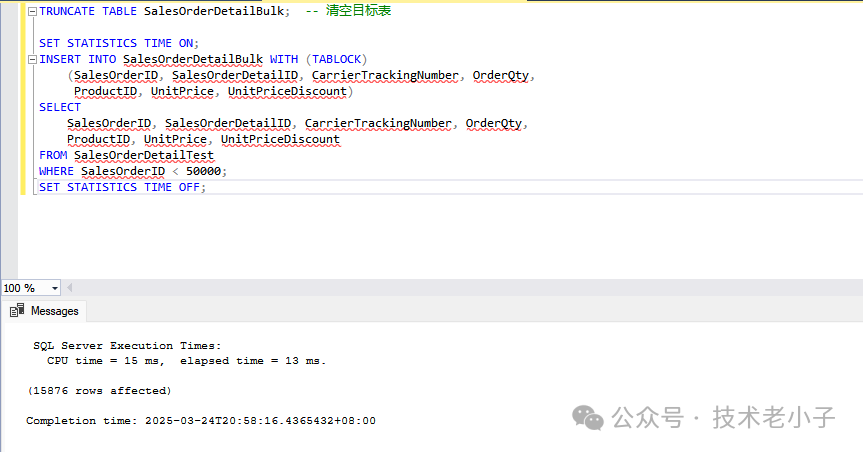
带有 TABLOCK 提示的插入 为方便比较,先清空目标表,然后使用 TABLOCK 提示:
TRUNCATE TABLE SalesOrderDetailBulk; -- 清空目标表 SET STATISTICS TIME ON ; INSERT INTO SalesOrderDetailBulk WITH (TABLOCK) (SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber, OrderQty, ProductID, UnitPrice, UnitPriceDiscount) SELECT SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber, OrderQty, ProductID, UnitPrice, UnitPriceDiscount FROM SalesOrderDetailTest WHERE SalesOrderID < 50000 ; SET STATISTICS TIME OFF ;
因为使用了表级锁和最小日志记录机制,执行时间往往会显著缩短,尤其在数据量更大的情况下效果更明显。
性能对比与注意事项 在上面的示例中,通常会出现以下结论:
不使用 TABLOCK 可能耗时更长,SQL Server 需要更多的日志写入。同样在并发场景下,可能有一定锁冲突,但不会一次性全表锁定。 使用 TABLOCK 在批量插入时速度会明显加快,但插入期间禁止其他事务对该表进行更新、插入或删除,直到操作完成。 需要注意以下几点:
表锁时机 TABLOCK 会锁住整个目标表,在多用户访问频繁的线上 OLTP 系统中需慎用。 日志空间 虽说最小日志记录会减少写入量,但在非常庞大的插入规模下仍会对事务日志造成压力,需确保数据库日志文件有足够空间。 并行插入 SQL Server 版本和数据库兼容级别可能影响并行度,如果想发挥最大化效果,需确认实例和查询设置允许并行执行。 总结 TABLOCK 提示是 SQL Server 为了应对大规模数据载入所提供的非常实用的手段之一。在临时表操作、批量数据迁移和数据仓库加载等场景中,通过 最小化日志写入 和 开启并行插入 ,往往能成倍缩短插入时间。不过,需要根据实际业务需求,综合考虑 表锁定 带来的影响和可接受度,再决定是否使用 TABLOCK 。在合适的场景中合理运用,可以为整体加载流程带来显著的性能提升。
阅读原文:原文链接






 400 186 1886
400 186 1886