字符编码:从基础到乱码解决
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
问题的引入#在日常开发中,当我们尝试将中文输出到控制台时,点击编译。这时,细心的读者可能会关注到 VS 的控制台会输出一段这样的警告(也有可能是团队规定不允许有警告出现🌝):
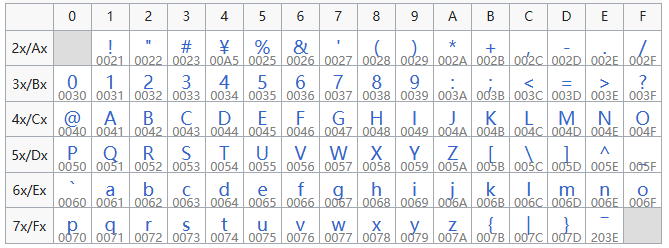
同时你心心念念的中文,输出到控制台却成为了乱码。为什么会出现这种问题呢? 这一系列的问题,归根结底,就是一个字符在计算机中,应该怎么样来表示。也就是字符的编码问题。所以,让我们先来了解了解,现代计算机体系中的编码模型是什么样的。 这一系列问题,追根溯源,其实就是一个字符在计算机中该如何表示的问题,即字符的编码问题。那么,我们先来了解一下现代计算机体系中的编码模型是怎样的。 字符编码模型#Unicode 字符编码结构模型分为 5 层,下面我们以一个“汉”字为例,为大家介绍这 5 层。 抽象字符集 (Abstract Character Set) ACR#待编码字符集,定义字符的逻辑集合,不涉及具体的编码逻辑。这一层仅确定“汉”字属于某个字符集。(像 GB2312 就只收录了 6763 个常用的汉字和字符,一些生僻字就没有被收录进来。又比如 ASCII 中就没有中文字符。) 编码字符集 (Coding Character Set) CCS从抽象字符集(ACR)映射到一组非负整数,也就是为每一个字符分配一个唯一的二数字(码位/码点)。例如:Unicode、ASCII、USC、GBK等编码。 在 Unicode 中,“汉”,表示成:\u6C49,而在 GBK 中,“汉”,表示成:0xBABA。 字符编码表 (Character Encoding Form) CEF一个从一组非负整数(来自 CCS)到一组特定宽度代码单元序列的映射。我们常说的 UTF-8、UTF-16、UTF-32 就是一个字符编码表。他规定了在抽象字符集中的“非负整数”怎么用字节表示。 例如在 UTF-8 中,“汉”字用三个字节表示:0xE6B189。 字符编码方案 (Character Encoding Scheme) CES一个从一组代码单元序列(来自一个或多个 CEF)到序列化字节序列的映射。 定义码元序列的存储方式,解决字节序等问题: 例如:
此层确保不同系统对同一编码单元序列的解析一致性。 传输编码语法 (Transfer Encoding Syntax) TES针对特殊场景的二次编码,如网络传输:
通过上面的介绍,相信你对现代编码模型的五层有了基本的了解。感兴趣的读者可以去看 Unicode technical report #17。 讲完了字符编码模型,接下来我们来了解一些常见的字符编码标准及其特点。 常见字符编码相信大家在日常的开发中,经常听到 Unicode、GB2312、GBK、UTF-8、UTF-16、UTF-32、ANSI,却又对这些概念比较模糊。首先要明确一点的是,Unicode、GB2312、GBK 都是编码字符集,而UTF-8、UTF-16、UTF-32 则是 Unicode 的编码字符表。ANSI 比较特殊,我们待会再具体介绍。 由于篇幅限制,对各个编码的具体编码模式感兴趣的读者可以在参考文献中自行了解。 ASCII#ASCII,全称American Standard Code for Information Interchange(美国信息交换标准代码),于 1963 年发布。标准 ASCII 采用 7 位二进制数来表示字符,因此它最多只能表示 128 个字符。 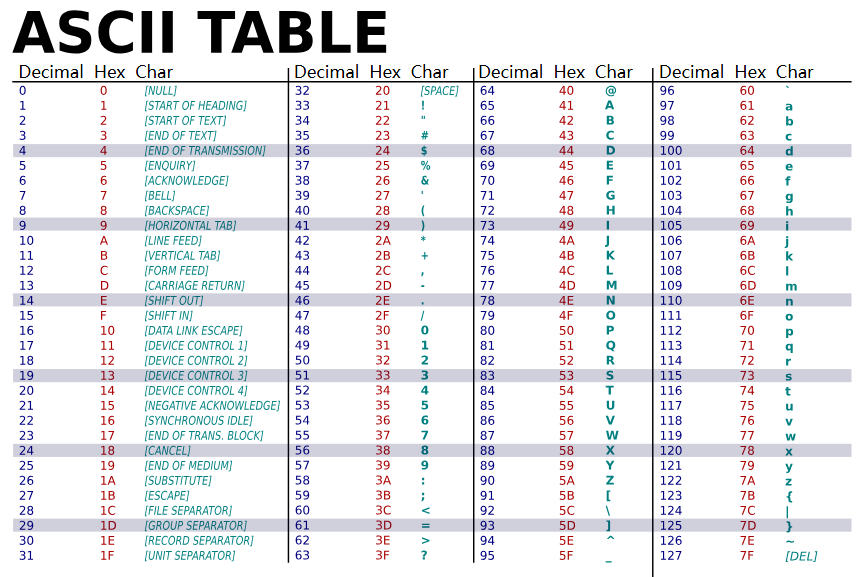 ASCII 编码虽然解决了英语的编码问题,但中文怎么办呢?汉字有那么多字。此时,就有了 GK2312 编码。 GB2312GB2312,又称 GB/T 2312-1980,全称《信息交换用汉字编码字符集·基本集》,与 1980 年由中国国家标准总局发布。GB2312 收录共收录 6763 个汉字,其中一级汉字3755个,二级汉字3008个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、注音符号、俄语西里尔字母在内的682个字符。 GB2312 使用两个字节来表示,第一个字节称为“高位字节”,对应分区的编号(把区位码的“区码”加上特定值);第二个字节称为“低位字节”,对应区段内的个别码位(把区位码的“位码”加上特定值)。
Unicode随着计算机技术在全世界的广泛应用,越来越多来自不同地区,拥有不同文字的人们也加入了计算机世界,同时也带来了越来越多的种类。在 1991 年,由一个非盈利机构 Unicode 联盟首次发布了 The Unicode Standard,旨在统一整个计算机世界的编码。 Unicode 的编码空间从 具体编码方式可以参考:彻底弄懂 Unicode 编码 GBK由于 GB2312 只收录了 6763 个汉字,有一些 GB2312 推出之后才简化的汉字,部分人用名字、繁体字等未被收录进标准,由中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订了 GBK 编码。GBK 共收录 21886 个汉字和图形符号。 UTF-8、UTF-16、UTF-32Unicode 转换格式(Unicode Transformation Format,简称 UTF),一个字符的 Unicode 编码虽然是确定的,但是由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对 Unicode 编码的实现方式有所不同。所以就有着不同的 Unicode 转换格式:UTF-8、UTF-16、UTF-32。 UTF-8UTF-8(8-bit Unicode Transformation Format)是一种用于实现Unicode的编码方式,它使用一到四个字节来表示一个字符。UTF-8具有良好的兼容性和效率,能够与ASCII字符集完全兼容,对于其他语言字符也能够以较高效的方式进行编码。 UTF-8 采用下面的规则来编码
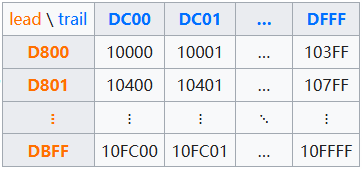
UTF-8 BOMBOM,全称字节序标志(byte-order mark)。目的是为了表示 Unicode 编码的字节顺序。使用 BOM 模式会在文件头处添加 字节序(Endianness)是指多字节数据(如一个整数或一个字符的多字节表示)在内存中的存储顺序。而对于 UTF-8 中,每个使用UTF-8存储的字符,除了第一个字节外,其余字节的头两个比特都是以"10"开始,除了第一个字符以外,其他都是唯一的。 但是 Unicode 标准并不要求也不推荐使用 BOM 来表示 UTF-8,但是某些软件如果第一个字符不是 BOM (或者文件里只包含 ASCII),则拒绝正确解释 UTF-8。 UTF-16UTF-16 把 Unicode 字符集的抽象码位映射为 16 位长的整数(即码元)的序列,也就是说在 UTF-16 编码方式下,一个 Unicode 字符,需要一个或者两个 16 位长的码元来表示。因此 UTF-16 也是一种具体编码。 Unicode 的基本多语言平面(BMP)内,从U+D800到U+DFFF之间的码位区段是永久保留不映射到Unicode字符。UTF-16就利用保留下来的0xD800-0xDFFF区块的码位来对辅助平面的字符的码位进行编码。 UTF-16 采用下面的方法用来编码:
同样我们也以“汉”字为例,它在 Unicode 中为:U+6C49,处于 BMP 中,所以直接用 0x6C49 表示。而另外一个以U+10437编码(𐐷)为例:
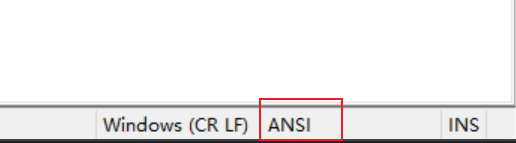
UTF-32#Unicode-32 直接采用 4 个字节来存储 Unicode 码位。这种编码格式的优点是能够直接用 Unicode 码位来索引,但同时,相比于其他编码(UTF-8、UTF-16),浪费空间,所以应用并不广泛。 ANSI#当我们创建一个文本文件,并用 Notepad++查看其默认编码时,会看到一个 ANSI
那么 ANSI 是什么编码呢?简而言之,ANSI 不是某一种特定的字符编码,而是在不同系统中,表示不同的编码。 输入字符集与执行字符集
例如:输入字符集为GB2312时,"中文"两个字,对应的二进制是:
而输入字符集为UTF-8时则为下面:
而执行字符集,可以通过显示设置字符集来修改: 在编译器中显式设置输入字符集和执行字符集。对于GCC编译器,可以使用 如果输入字符集和执行字符集不一致,编译器需要在编译过程中进行字符编码的转换。当两者不一致时,编译器需进行编码转换,可能引发:
所以,尽量将两个字符集设置成一样的。 代码页在计算机发展的早期阶段,ASCII编码(美国信息交换标准代码)是主流的字符编码方式,它使用7位二进制数表示128个字符,包括英文字母、数字和一些标点符号。然而,ASCII编码无法满足多语言环境的需求,因为世界上有成千上万种语言和符号。 为了解决这个问题,操作系统和软件开发商引入了代码页的概念。代码页允许系统支持多种字符集,尤其是那些超出ASCII范围的语言字符。在Windows操作系统中,代码页是系统用来处理文本数据的机制。例如,当用户在系统中输入或显示文本时,系统会根据当前的代码页设置来解释这些字符。 假设你有一个文本文件,内容是中文字符“你好”。如果这个文件是用GBK编码保存的,那么它的字节序列可能是 再探乱码看到这里,相信各位读者对字符编码已经有些一些基础的了解。所以,下面让我们尝试解答刚开始提出的问题:
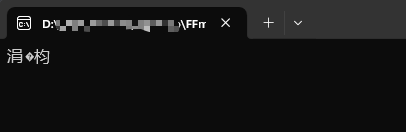
为什么控制台会输出乱码?假设有这样一段代码: 运行起来后,会发现输出到控制台是这种情况:
这个问题的影响因素有两个:
首先,在 Windows 下,控制台的默认编码是当前系统的代码页(通常是 GB2312),所以如果你输出到控制台的字符不是当前代码页编码对应的字符,那么就会发生乱码。当前系统的代码页通过 cmd 执行命令
当我们输出到控制台时,按照 GB2312 编码去解析这 6 个字节时,我们会得到: 涓(E4B8)(ADE6)枃(9687),其中 ADE6 在 GB2312 中为错误编码,所以会显示一个问号。 根据这个思路,我们有两种方法解决这个问题:
第一种我们通过执行 第二种,就是修改文件的字符编码格式,改成 GB2312。怎么改我就不赘述了,网上一大把。 该字符在当前源字符集中无效?这一个问题与输入字符集有关,当文件编码与编译器预期不一致,例如你的文件是GB2312编码,但编译器(如MSVC)默认使用UTF-8(代码页65001)来解析源文件。GB2312和UTF-8是不兼容的编码格式,导致编译器无法正确解析文件中的字符。 笔者的 Visual Studio 工程命令行有一个
虽然第二个字节符合 10xxxxxx 的格式,但第一个字节的值 QString 一些字符相关的函数在 QString 中有许多的转换函数:
QString 是以 UTF-16 的格式存储的字符:
所以,调用上面这些函数就是用指定的格式读取字符,并将这些字符转换成 UTF-16 格式。参看下面的例子: 输入字符集为GB2312时:
输入字符集为UTF-8时:
最后的最后#感谢各位读者阅读本博客,本博客内容在创作过程中,参考了大量百科知识以及其他优秀博客,并结合笔者自身在实际工作中遇到的相关问题。笔者希望通过这篇博客,能为各位读者在字符编码这一块提供一些有价值的见解和帮助。 转自https://www.cnblogs.com/codegb/p/18768600 该文章在 2025/3/14 9:53:11 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886